1. 输入法语言模型简要理解
- 简要概括:
- 输入法目的是为了得到一个文字序列(通顺的字词或句子),所以它是一个语言模型。
- 语言模型:
- 语言模型的概率特性:p(W1,W2...) = p(W1)*p(W2|W1)*p(W3|W1,W2)=p(Wn|W1,...Wn-1)
- 每个词的概率计算量太大了,所以使用2-Gram:P(Wn|Wn-1),只与上一个Token相关。
- 单纯的N-gram是处理解决文本序列概率的模型,对于输入法来说:输入和输出是不同的序列,加上2gram性质,直接想到的模型便是HMM,因为它快。
机器学习:HMM
- 由2-gram与输入法(拼音->文字)的特性,第一想到的模型便是HHM(观测序列 to 状态序列)
- 元素:观测序列【用户输入拼音】、隐含状态【想输入的文字】
- 一些细节:
- 【shu‘ru’fa】用户一般不会【‘】切分的话,可以使用jieba的词典策略:构建一个大的trie树
- 缺点:
- 特征局限性,不足以捕获整个上下文信息(比如输入法中,不足以捕获之前已输入文字的更多信息)
深度学习:深度学习模型
- 1.使用RNN循环单元提取特征,能够较好的利用已输入的文字信息,预测下一个Token
- 2.构建输入需要到输入序列的Seq2seq。
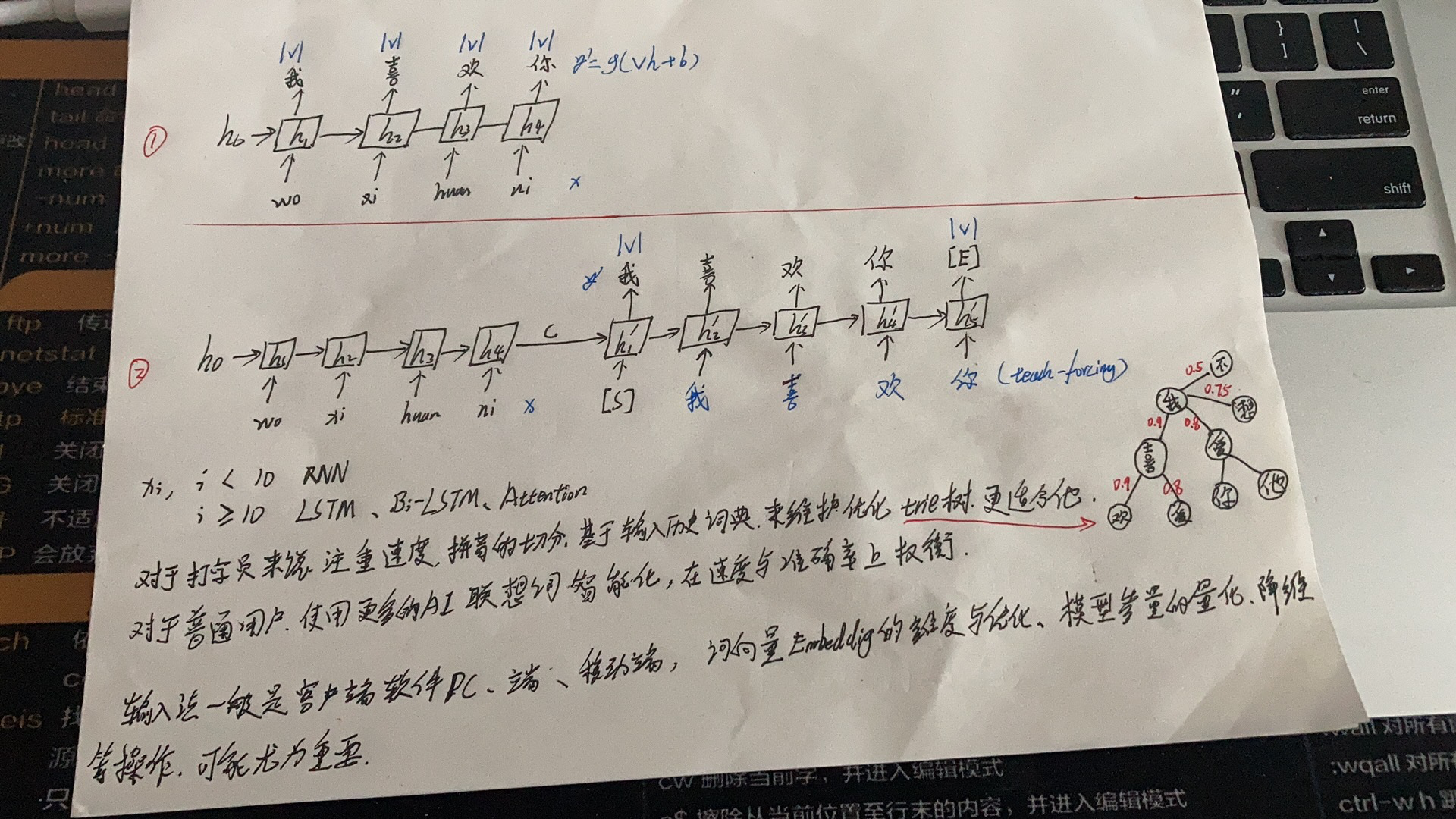
- 以上是个人basene理解,每家输入法公司都有一套魔改模型,用不同手段多维度表征Embedding。
- 当今流行的输入法,将大量的搜索引擎、翻译技术介入其中,纠错、新词发现、历史记忆、多模态生成等NLP手段,使输入法也越来越智能化。